DATA
Yes. That’s a big topic. This is just purely some messy and random notes on the general topic of databases, data, and big data.
Mostly based on my reading of:
- Designing Data Intensive Applications
- stuff you should know about databases
- use the index, Luke
OLTP vs. OLAP
Different workloads require different databases, and ultimately different. Generally we break these systems up into two broad categories.
- OLTP = Online Transaction Processing - transaction heavy. Real time, capture/persistence of data. Optimized for availability and speed.
- OLAP = Online Analytical Processing - analytics heavy. Optimized for heavy/complex queries.
LSM and B trees
These are several popular data structures for how databases organize data and create indexes. These are basically two approaches to organizing data for key/value lookup.
- LSM = log structured merge - when writing data, you also write the data in a log first, then later the log is (somehow?) used for the key/value lookup. This is attractive for applications with a high volume of inserts. Good for transactional workloads.
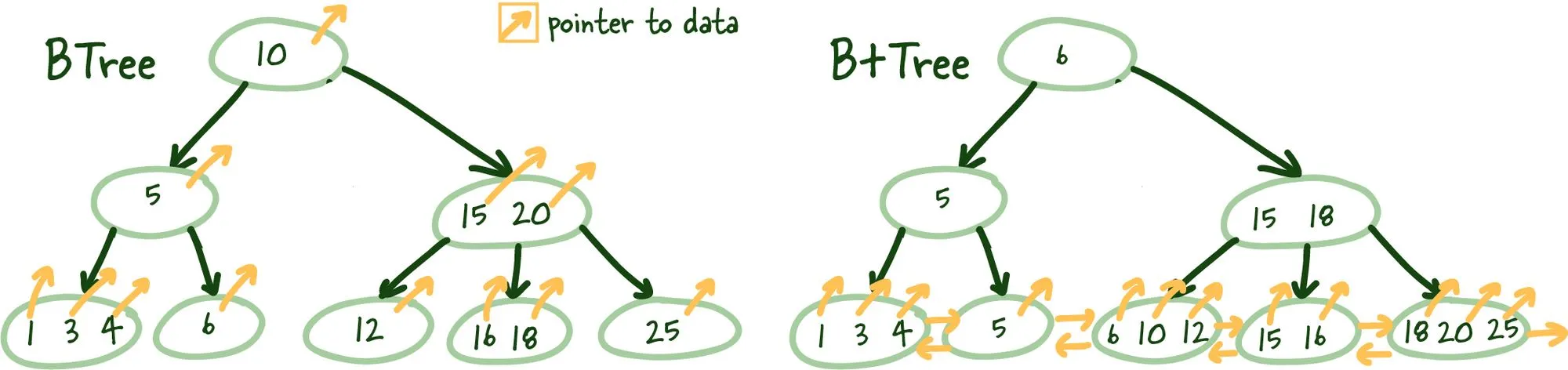
- B tree - Instead of depending on the write log for key/value lookup, the b tree uses a self-balancing tree structure of 4kb segments. A B tree is, indeed, a tree. Each node is a piece of data. It’s “self-balancing” in the sense that the data stays sorted across reads/insertions and and deletions. Oh yeah, also, insertions/reads/deletes are all logarithmic in time, so good perf.
- B+ tree - A variant of B tree that uses a slightly different strategy for organizing data. Instead of having each node be a piece of data, data ONLY resides on the leaf nodes. The parent notes are, instead, indicators of the highest value of its child nodes. This makes for even faster reads and searches, having to do less traversal of the tree.
Encodings…more than just JSON!
Typically when making apps, I always think of JSON as the ultimate encoding for data transfer. Turns out, this is a lie. JSON is just good for web apps, basically. When it comes to storing huge huge huge amounts of data, JSON is not a good choice. Nor is XML or CSV, two other text-based readable formats.
There are several drawbacks, such as:
- There’s no schema outside of the record itself — it’s schemaless.
- You have to store the keys in the record itself, which would probably be duplicated between many documents.
- Poor support for big numbers and high-precision floats.
- etc.
Instead, we have encodings like Protocol Buffers aka protobuf, which is from google. There’s also Thrift from facebook and Avra from apache.
All of these encode data in a way that saves a tooon of space on disk. The way it works:
- You have schemas, separate from the documents themself. The schemas define aliases for keynames (instead of
usernameit would be1, etc.) and define the data types. - Each record is stored as a byte string according to the schema.
- So basically binary + schema
- These encodings are also noteworthy for providing clear paths to forward + backward compatibility
An example of a protobuf schema:
message Person {
required string user_name = 1;
optional int64 favorite_number = 2;
repeated string interests = 3;
}
Forward + Backward compatibility
- Forward Compatible - Old code can read new data.
- Backward Compatible - New code can read old data.
ETL
Extract, transform, load. Basically referring to a pipeline that takes data from an application and harvests it into a data lake for analytics. Moving data from an OLTP system to an OLAP system.
ACID
Atomicity, Consistency, Isolation, Durability
usedto describe databases that support transactions, but mostly a marketing term. compare with BASE: Basically Available, Soft State, Eventually consistent
Related: a “dirty read” is reading from a database between two transaction commits.
