ENCODINGS
Something every developer should know.
Let’s go, roughly chronologically.
ASCII
Originally based on the english language, ASCII consists of 128 characters, all of which are represented (encoded) in 7-bit integers.
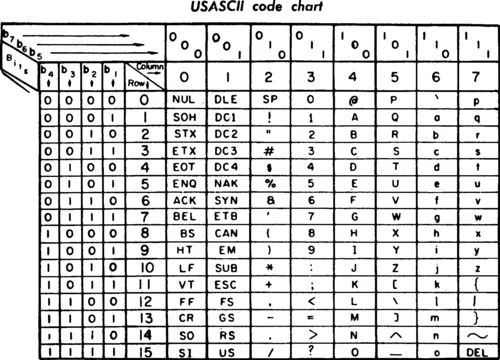
Since this is a super basic/bare bones text encoding, a lot of people misappropriate ASCII to mean “plain text”. This is wrong. We’ll get to this later.
Work on the standard started as early as 1961, and it’s still ubiquitous today. For example, the C programming language still uses ASCII as the encoding for source code.
At/around the same time as ASCII, there was a TON of other character sets consisting of 128 8-bit characters. OEM, EBCDIC, and others.
These worked well, until you encounter languages other than English.
Unicode
Unicode was designed over the course of about 10 years, totally in response to the above question of: how to encode languages which aren’t english?
It’s a single character set that includes everywriting system on the planet. It also includes emoji.
Unicode works by representing a character to a code point. This is basically a theoretical concept.
It looks like this: U+0639. The U part means “unicode” and the number is hexadecimal.
Please note, Unicode is not actually an encoding. It’s a standard. We still need an encoding.
UTF-8
One would look at the hexadecimal values of Unicode characters in comparison with, say, ASCII’s 8-bit encodings and say gosh. That’s a lot of gas guzzling size just for one character.
Meet UTF-8. An encoding for Unicode. It’s a “variable width” encoding, which means for characters that don’t require a lot of space (such as “A” or ”-”, english characters, etc.), the character will only occupy a small amount of space.
For example, for the first 128 characters, which correspond to ASCII btw, each character only takes 1 byte. From there characters get fatter as needed.
There are other Unicode encodings, such as UTF-32, UTF-7 (some weird compatibility layer, now deprecated) and GB 18030 (a character encoding blessed by the Chinese Gov’t).
UTF-8 is the dominant encoding of the web, over 97% of websites are encoded using this encoding. Also UNIX systems, like all smartphone operating systems and most personal computers. Basically it’s the go-to encoding.
That being said, here’s a useful tidbit of web perf.
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8">
Why? Well, an HTML document is not necessarily UTF-8, and a browser will start parsing the document without knowing the encoding. As soon as it knows what the character encoding is, it starts over. So put that meta tag as early as possible in your HTML document, for perf reasons.
Conclusion?
Not much to say here. These are just a few encodings out of hundreds of text encodings that exist out there.
Other Fun Stuff
- Japanese Ghost Characters - weird unicode characters that aren’t actually part of the Japanese language that made it into the spec, such as 妛