Week 1: Introduction to Deep Learning
Videos:
- What is a neural network?
- Supervised Learning with neural networks
- Why is deep learning taking off?
What is a Neural Network?
Vocab:
- RELU - Rectified Linear Unit. Basically a linear trend that doesn’t go below 0.
The lecturer introduces a great example of how a neural network can be used for prediction: housing prices. There are many aspects that influence the price of a home, such as:
- Zip Code
- Number of bedrooms
- Year it was built
- Size
- Neighborhood
- Walkability
- School Quality
These different elements can each be seen as a node in a neural network.
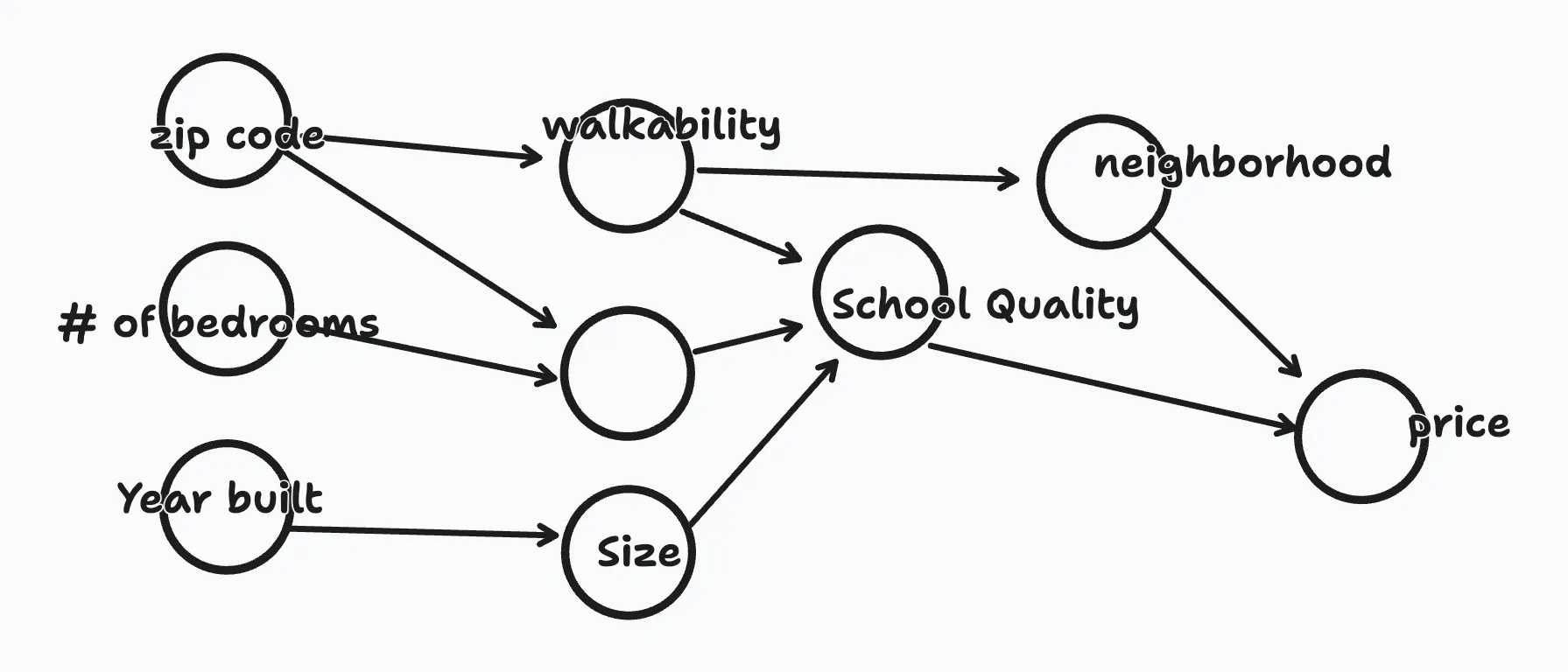
All of these different factors can help predict the price of a house, and they also predict eachother in different layers. The furthest left layer is the input (x), the first right is the output (y).
Every node on the input side is connected to every one of these circles in the middle. And the remarkable thing about neural networks is that, given enough data about x and y, given enough training examples with both x and y, neural networks are remarkably good at figuring out functions that accurately map from x to y.
We don’t even necessarily know anything about the middle layers. That’s private to the neural net.
Supervised Learning with Neural Networks
In this video, the lecturer covered a few more basics about, basically, what is machine learning.
- Supervised Learning: training a neural network on known data. We know the value of x and y, we give a neural net x and try to get it to return y.
- Structured Data
- Unstructured Data
- Standard Neural Network - Traditional predictive neural network, good for e.g., real estate and online advertising.
- RNN - recurrent neural network. Good with one-dimensional sequential data, like, for example natural language.
- CNN - convolutional neural network. Good for image data.
Why is Deep Learning taking off?
This can be answered pretty simply: we have a wealth of labeled data now, thanks to social media and the digitization of literally everything.
Also, GPUs and cloud computing. That’s made a huge difference.
Less obvious to me previously was the algorithmic functions that we use for training models. We’ve recently switched from sigmoid functions to RELU functions for the activation function of neural networks. I’m not sure what this implies exactly, but it means we can train models much faster, due to the algorithm called “gradient descent” being able to work much faster.
Vocab:
- lowercase
mwill refer to our training data set in future videos.