How does stable diffusion work?
This is a rough overview in my own words about how does stable diffusion work.
This is mostly based off of these resources:
In Brief
The most basic, oversimplified explanation of how does stable diffusion work: the model is trained to turn an image of random noise into a meaningful image based on the input.
Components of Stable Diffusion
Firstly, there are different components and stages that make up “stable diffusion”. Important to note: stable diffusion is a text to image model. That means there is both a text and image neural networks at play here.
- Unet - The Unet(or u-net) is a convolutional neural network. More specifically, it’s a particular architecture of neural network that is good at image segmentation. So, basically, it builds the image.
- VAE - Variational Auto-Encoder.
- Text Encoder - Usually CLIP from open AI. This is optional, technically, and generally treated as a variable component of Stable Diffusion.
So, in a way, Stable Diffusion is comprised of three types of neural networks working in concert.
Forward and Reverse Diffusion
In a very, very simplified way, Stable Diffusion works through a process of forward and reverse diffusion. The word “Diffusion” here meaning the physical phenomenon — like a drop of ink falling into a cup of water. As it enters the water, it diffuses through the space. Eventually the water just becomes a murky dark liquid.
Stable diffusion is like that, except the water is gaussian noise, the ink is the result of the neural net, and the end murky dark liquid is a beautiful realistic image.
Stable diffusion works using two concepts:
- Forward Diffusion: training, via deliberately noising an image.
- Reverse Diffusion: inferencing, using the trained model to inference an image out of noise.
Training
Firstly, we need to train our model. We do this by showing the Unet, step by step, the process of adding noise to an image. This is called forward diffusion.
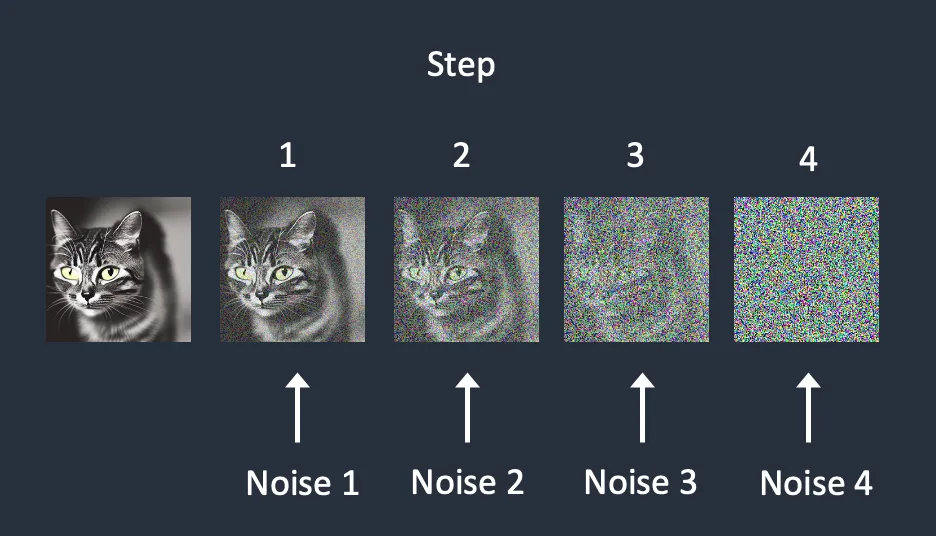
As we train it, for each step, we have it guess how much gaussian noise was added to the image. And in the classic machine learning fashion, iteratively optimizing the model based on its performance at guessing how much noise we added to the image.
Basically, at the end, our Unet is a very good noise predictor. It’s very good at telling us how much noise is in a given image, and that’s the key inference we want it to be able to make.
Inferencing
As Billy put it so eloquently: it’s like seeing jesus in a piece of toast.
The image generation process, or inference, is the exact opposite — we want the model to use what it learned to guess how much noise is added to an image that we’re showing it. The Unet guesses how much noise is added to the current image, and we then remove that amount of noise from the iamge. Then repeat 50 times or so.
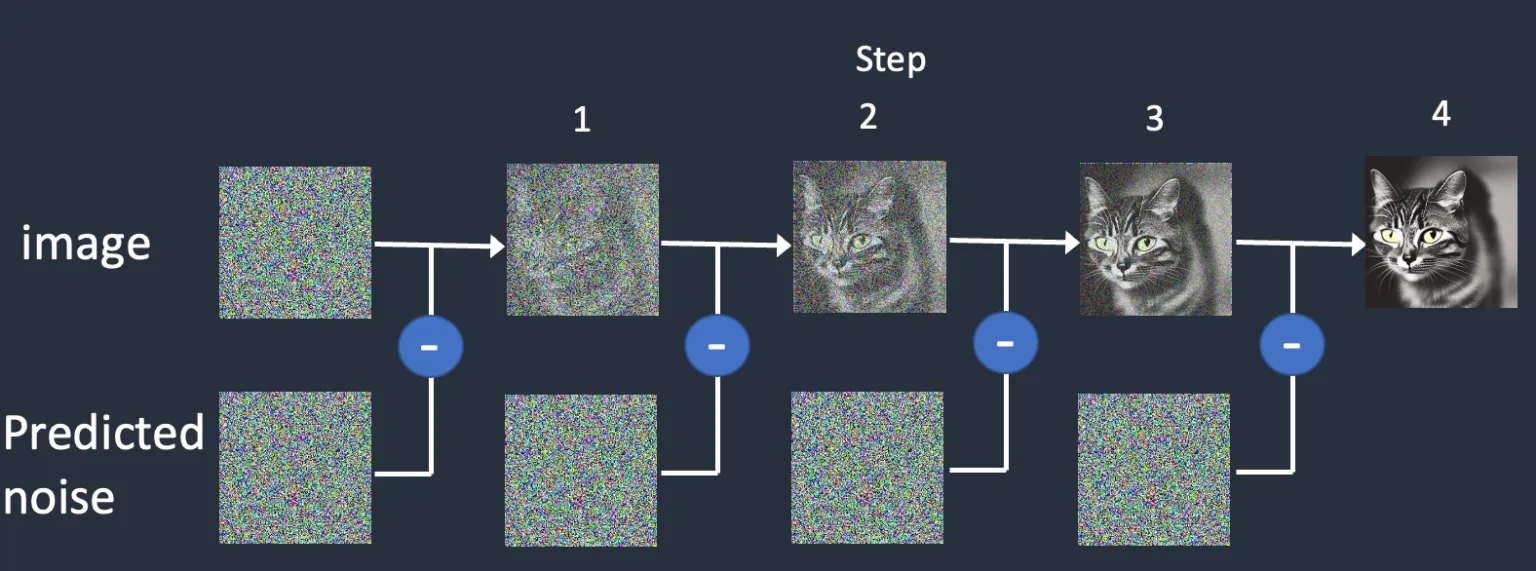
This is called reverse diffusion, since we are de-diffusing the image. We’re removing the ink from the image. I think I got my ink/water metaphor mixed up.
Pixel Space vs. Latent Space
Unfortunately, the above is a lie. That’s not how stable diffusion works. If we were to do things that way, having our model process pixel by pixel, guessing what is noise in the given image, that would take a toooon of time.
Think about it: a 512×512px image with three color channels (red, green, and blue) is a 786,432-dimensional space! There’s no way any GPU could possibly handle that workload.
This is actually how the previous generation of image generation AI models worked — in pixel space. Like Dall-e, for example.
So, that brings us to Stable Diffusion’s true breakthrough: speed. Instead of doing the inference pixel by pixel, Stable Diffusion does the inference in latent space, and uses the Variational Auto Encoder (VAE) to encode and decode between latent space and pixel space.
What is latent space?
- Compression - 4x64x64 dimensions for a 512x512px image, vs. 3x512x512 if we’re going based on pixels.
- Manifold Hypothesis
- Basically there’s a bunch of repetition and predictability in nature and images, the VAE is aware of that and can capture and compress an image in a representation many dimensions smaller than an image without losing information.
How do we run reverse diffusion in latent space?
Ha! Finally. Now this can start to make sense.
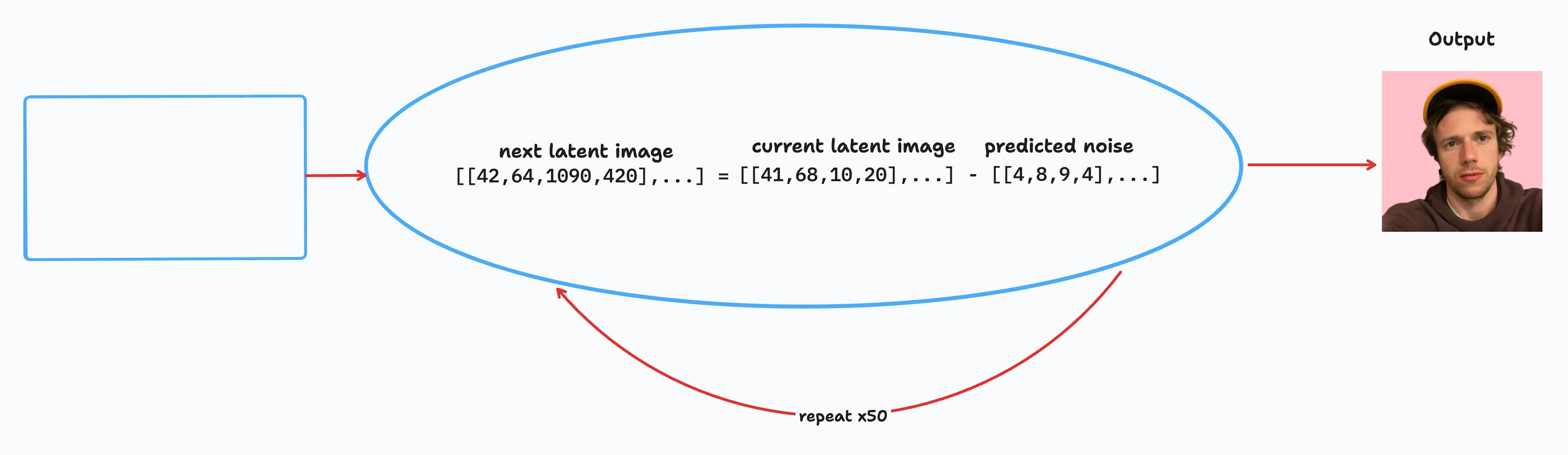
- From the inputs (which we’ll get to later), a random latent space matrix is generated.
- The noise predictor (our Unet) looks at the latent-space matrix and estimates the noise in it — inference!
- The estimated noise it gave is then subtracted from the latent matrix, and that’s our input for our next step.
- Steps 2 and 3 are repeated up to specific sampling steps.
- The VAE then converts the latent matrix to the final image.
Conditioning, Inputs, Attention
Okay, so we understand the noise, the latent space, and seeing jesus in a slice of toast. But that doesn’t explain one part: Stable Diffusion is a text to image model, not just a “generate random shit out of gaussian noise” model.
That’s where what we refer to as conditioning comes into play. The purpose of conditioning is to steer the noise predictor so that the predicted noise will give us what we want after subtracting from the image.
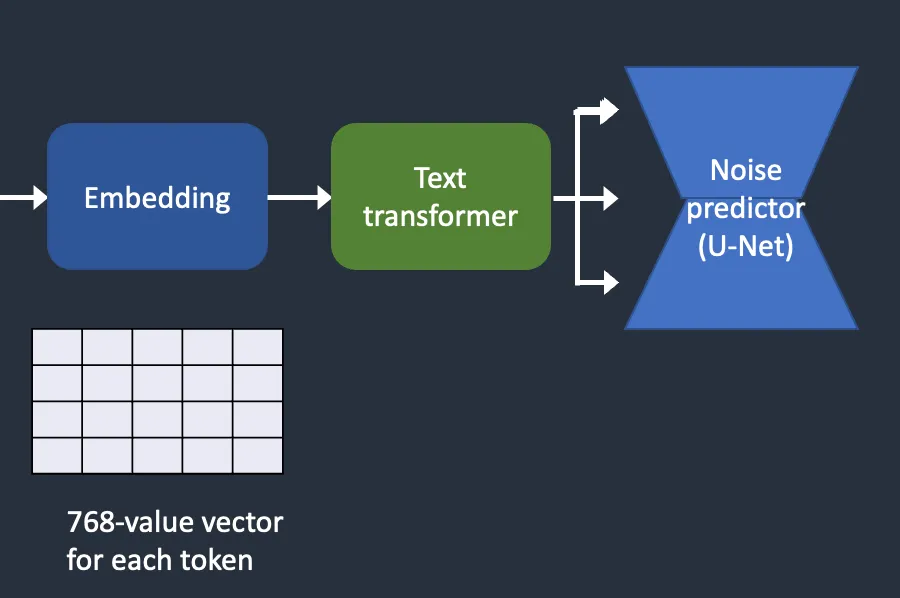
Text Embeddings
So, we go from prompt -> tokens -> embeddings.
Token is an arbitrary unit of language something close to 1 word. In 1000 words there are 750 tokens, ish.
Text embeddings are a representation of a token in a language model. For example, guy, man, and boy will all have realitively close or identical embeddings. It’s a representation of the actual meaning.
Embeddings are important beyond just mapping word to a meaning in a network. Embeddings can also house complex or abstract concepts in a compact or centralized unit. For example, you can use custom embeddings to fine tune a model for a specific purpose, or use a token to store a reference to a specific concept.
How are text embeddings used by the Unet?
Before embeddings can be used by the Unet, our noise predictor. they need to go through the text transformer. This is like a universal layer that all conditioning (not just text) needs to go through before being used by the Unet.
Cross-Attention
TODO
”Stochastic”
- Seed -> latent space -> initial latent space matrix.
Noise Schedule
One thing that particular justifies some extrapolation is the so-called “noise schedule”. As we know, stable diffusion essentially works by calculating the predicted noise in the current image (tensor in latent space, really), then creating a new tensor by subtracting the predicted noise from the current tensor, step-by-step iteratively.
Usually we repeat this for about about 50 steps before the “final” representation of the image is cooked, which we then pass over to the VAE for it to convert back to a “normal” image in pixel space.
SO, if we do it 50 times, is that because the Unet is just bad at predicting the noise in the latent image?
In fact, no. Recall my previous investigation on Stable Diffusion lead me to the concept of a Markov Chain. Each iteration, each step, is in fact predicting the expected amount of noise at that current state. It’s not a one-shot — each step has an expected amount of noise, and the model is optimized to predict that particular amount of noise.
This is where the noise schedule comes in. Each step has an expected level of noise, and the level is determined by the noise schedule. The noise schedule is, of course, decided during training, not inference.
How do different types of stable diffusion work?
- Text-to-image
- Image-to-image
- Depth